
nvidia Tesla K80 24G
日期:2017-05-23 11:17:38 / 人气: 3568

Tesla K80的参数
Tesla K80 双GPU 加速器可透过一卡双 GPU 提供双倍传输量,内置24GB GDDR5 存储器,每颗 GPU 有 12GB 存储器,比上代Tesla K40 GPU 提供多两倍存储器处理更大的资料集分析。Tesla K80 内建4,992 CUDA 平行运算核心,可比仅用CPU 运算提升高达10 倍应用加速效能,加上采用动态NVIDIA GPU Boost 技术,可根据个别应用灵活提升GPU 时脉,而且更透过动态平行运算架构,让用户可快速分析关联式和动态的资料结构。
英伟达 NVIDIA Tesla K80 24GB GPU加速运算卡
最高实际性能
实际应用性能高于纯浮点性能 (Raw Flops)。 计算专业人士依赖举足轻重的应用来加速探索与深入了解。 这一平台从全球最快的加速器开始,现已包含可靠的基础架构、监控和管理基础架构的能力以及在需要时快速移动数据的能力。 NVIDIA Tesla 加速计算平台可提供所有这些特性,在科学、分析、工程、消费级以及企业应用中带来前所未有的性能。
全球最快的 GPU 加速器
- Tesla K80 GPU 加速器上的双精度性能高达 2.91 TFlops,单精度性能高达 8.74 TFlops
- 利用 NVIDIA® GPUBoost™ 技术时每一款应用的最高性能
- 大容量板载内存可提升大型数据集的性能 (Tesla K80 GPU 加速器为 24 GB)
- 极高的内存带宽可提升吞吐量以便在需要时确保数据可用 (Tesla K80 GPU 加速器为 480 GB/s)
- 纠错码(ECC)为内部GPU内存提供了强大的数据可靠性并为外部GDDR5内存提供了ECC保护盒动态页面引退机制。
用于服务器的 TESLA K40 与 K80 GPU 加速器
利用 NVIDIA® Tesla® GPU 加速器为你最苛刻的数据分析与科学计算应用加速。 Tesla GPU 基于 NVIDIA Kepler™ 架构,旨在提供更快、更高效的计算性能。
从能源勘探到机器学习,数据科学家利用 Tesla 加速器可以轻松处理多达拍字节 (Petabytes) 的数据,而且速度比使用 CPU 时快 10 倍。 对计算科学家来说,Tesla 加速器可提供所需的处理动力,能够以前所未有的速度运行更大型的模拟。
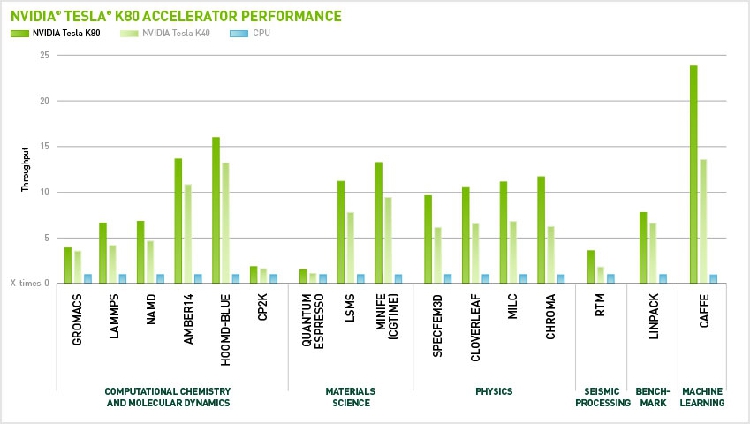
CPU: 12 cores, E5-2697v2 @ 2.70GHz. 64GB System Memory, CentOS 6.2. GPU: Single Tesla K80, Boost enabled or Single Tesla K40, Boost Enabled
SELECT THE TESLA GPU THAT'S RIGHT FOR YOU
Tesla K80 GPU 加速器
Tesla K80 GPU 是一款双 GPU 卡,它把带宽超高的 24 GB 内存和高达 2.91 TFlops 的双精度性能与 NVIDIA GPUBoost™ 结合到了一起,它是专为最苛刻的计算任务而设计的。 它十分适合那些不但需要一流计算性能而且还要求数据吞吐量大的单精度和双精度计算 马上免费试用Tesla K80加速器.
Tesla K40 GPU 加速器
Tesla K40 加速器配有 12 GB 内存,可提供 1.43 TFlops 的双精度性能。 Tesla K40 加速器是一款用于高性能计算与数据分析的灵活解决方案,它能够毫不费力地运行高性能计算与数据分析应用。
选择合适的 TESLA GPU
| 特性 | Tesla K801 | Tesla K40 |
| GPU | 2 颗 Kepler GK210 | 1 Kepler GK110B |
| 峰值双精度浮点性能 |
2.91 Tflops (GPU 动态提速频率) 1.87 Tflops (基础频率) |
1.66 Tflops (GPU 动态提速频率) 1.43 Tflops (基础频率) |
| 峰值单精度浮点性能 |
8.74 Tflops (GPU 动态提速频率) 5.6 Tflops (基础频率) |
5 Tflops (GPU 动态提速频率) 4.29 Tflops (基础频率) |
| 存储器带宽 (ECC关闭)2 | 480 GB/s (每颗 GPU 240 GB/s) | 288 GB/sec |
| 存储器容量 (GDDR5) | 24 GB (每颗 GPU 12GB) | 12 GB |
| CUDA 核心数量 | 4992 个 (每颗 GPU 2496个) | 2880 |
1 所示的 Tesla K80 的规格参数是两颗 GPU 的总和。
2 在启用 ECC 的情况下,6.25%的 GPU 内存用于 ECC 数据位。 例如,在启用 ECC 的情况下,如果内存总容量为 6 GB,那么用户可用内存容量为 5.25 GB。
Tesla 软件功能
NVIDIA® Tesla® GPU计算产品专为工作站以及数据中心的高性能计算而设计。 有许多 CUDA 软件特性都是专为 GPGPU 而设计的,而且只有 Tesla 产品才支持这些特性。 下表对此进行了总结。
|
软件应用程序
|
描述 | 支持 Matrix | 下载 | ||||||||||||||||||
|
Windows 的高性能驱动程序: TCC 驱 动程序
|
|
|
|
||||||||||||||||||
|
GPU 监控: nvsmi
|
|
|
|
||||||||||||||||||
|
GPU 集群管理
|
|
|
|
||||||||||||||||||
|
NVIDIA GPUDirect™ v1.0
|
|
|
下载
|
||||||||||||||||||
|
NVIDIA GPUDirect™ v2.0
|
|
|
|
注: CUDA 注册开发者 现在可以下载 CUDA 4.1 候选版本。
针对 WINDOWS 的 TCC 驱动程序
TCC (Tesla 计算机集群)驱动程序是一种用于 CUDA C/C++ 的 Windows 驱动程序,该驱动程序可实现远程桌面、服务并能够在 Windows 上减少 CUDA 内核启动的系统总开销。 请注意,TCC 驱动程序可禁用 Tesla 产品上的图形功能。
GPU 监控
针对 Tesl a的 GPU 监控软件可以利用 nvsmi 工具来获得。 该工具目前能够给出 GPU 温度、风扇转速以及 ECC 信息。 随着我们新增更多的 GPU 监控特性,nvsmi 将不断发展。
GPU 集群管理
NVIDIA® 与多家集群管理软件供应商均保持着合作关系,这些供应商支持基于GPU 的系统:
| – | Bright Computing |
| – | ClusterCorp Rocks |
| – | Platform Computing |
除了这些以外,CUDA 驱动程序还支持两种重要的特性:
| – | 排他模式: 只让特定应用程序访问某一 GPU |
| – | GPU 可视设备: 通过控制应用程序能够使用哪些 GPU,从而让集群管理软件能够管理 GPU 资源。 |
NVIDIA® GPUDIRECT™
通过消除不必要的 CPU 处理时间,NVIDIA GPUDirect 技术让 GPU 能够与 PCIe 总线上的其它设备更快地通信。 GPUDirect v1.0 让第三方设备驱动程序 (例如用于 InfiniBand 适配器的驱动程序) 能够直接与 CUDA 驱动程序通信,消除了在 CPU 上复制数据所需的处理时间。 GPUDirect v2.0 让同一系统中的多个 GPU 之间能够实现点对点 (P2P) 通信,避免了额外的 CPU 处理时间。